
I hold a Postdoc position at Tsinghua University, working with Prof. Jie Tang and Minlie Huang. I obtained my Ph.D. from Sichuan University in June 2023 under the supervision of Prof. Jianzhou Zhang, Prof. Rong Jin (Alibaba DAMO). Dr. Mang Wang (ByteDance). I am participating as one of the contributors to project VGen (通义万相) and SuperBench (清华大学-基础模型中心). I led project include ERD, C-Flat, ZeroFlow and INFTY Engine. All projects gained a total of 4,000+ stars.
My research lies at the intersection of computer vision and artificial intelligence. My research interests include Computer Vision, Continual Learning, Video Generation and Vision-Language Model. My vision is striving to build
🔥 News
- 2025.11: 🎉 ACL , MoZO accepted by AAAI 2026.
- 2025.09: 🎉 Initial version of INFTY is released.
- 2025.06: 🎉 VLM-CL, SAMora accepted by ICCV 2025.
- 2025.05: 🎉 ZeroFlow , Dual-Arch, gR_MoE-LoRA accepted by ICML 2025.
- 2025.03: 🎉 TDFusion accepted by CVPR 2025 as Highlight.
- 2025.02: 📖 We release a survey Parameter-Efficient Fine-Tuning for Foundation Models.
- 2025.02: 📖 We release a survey Generative Artificial Intelligence in Robotic Manipulation.
- 2025.02: 🎉 HAR Foundation Model accepted by Information Fusion (IF=14.80).
- 2024.09: 🎉 C-Flat accepted by NeurIPS 2024.
- 2024.06: 🎉 UniGrad-FS accepted by IEEE TII (IF=11.70).
- 2024.04: 🎉 R2KD accepted by IEEE TIM (IF=5.60).
- 2024.03: 🎉 InstructVideo accepted by CVPR 2024.
- 2024.01: 🎉 ArchCraft accepted by IJCAI 2024.
- 2023.07: 🎉 RLIP v2 accepted by ICCV 2023.
- 2023.07: 🎉 RLIP accepted by NeurIPS 2022 as Spotlight.
- 2022.03: 🎉 ERD accepted by CVPR 2022.
- 2021.12: 🎉 Pose-powered ReID accepted by Pattern Recognition (IF=7.50).
- 2021.10: 🏆 Win 1st Place on Webface260M SFR Track! @ICCV MFR Challenge.
- 2021.10: 🥈 Win 2nd Place on InsightFace unconstrained Track! @ICCV MFR Challenge.
- 2021.10: 🥉 Win 3rd Place on Webface260M Main Track! @ICCV MFR Challenge.
- 2021.10: 🥉 Win 3rd Place on InsightFace ms1m Track! @ICCV MFR Challenge.
- 2021.09: 🎉 One paper accepted by ICCV 2021 @workshop.
📝 Publications
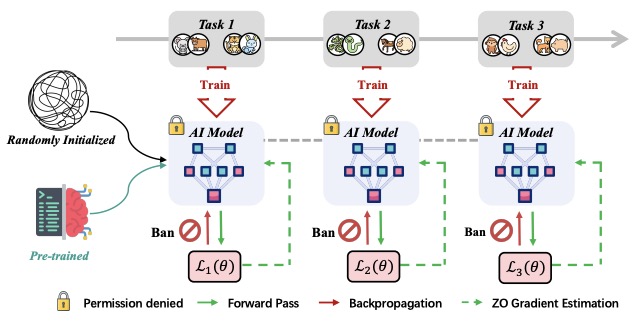
ZeroFlow: Overcoming Catastrophic Forgetting is Easier than You Think
Tao Feng, Wei Li, DiDi Zhu, Hangjie Yuan, Wendi Zheng, Dan Zhang, Jie Tang
- We introduce ZeroFlow, the first benchmark designed to evaluate gradient-free optimization algorithms for overcoming forgetting.
- We find that forward passes alone are enough to overcome forgetting. Maybe, once is all it takes!
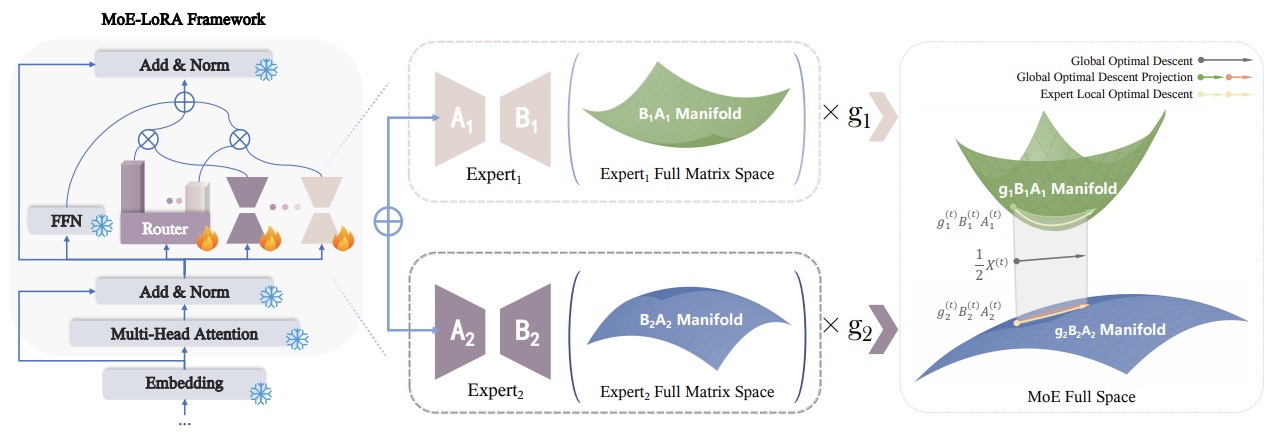
A Stronger Mixture of Low-Rank Experts for Fine-Tuning Foundation Models
Mengyang Sun, Yihao Wang, Tao Feng†, Dan Zhang, Yifan Zhu, Jie Tang†
- We propose a new training strategy for MoE-LoRA, to stabilize and boost its feature learning procedure by multi-space projections.
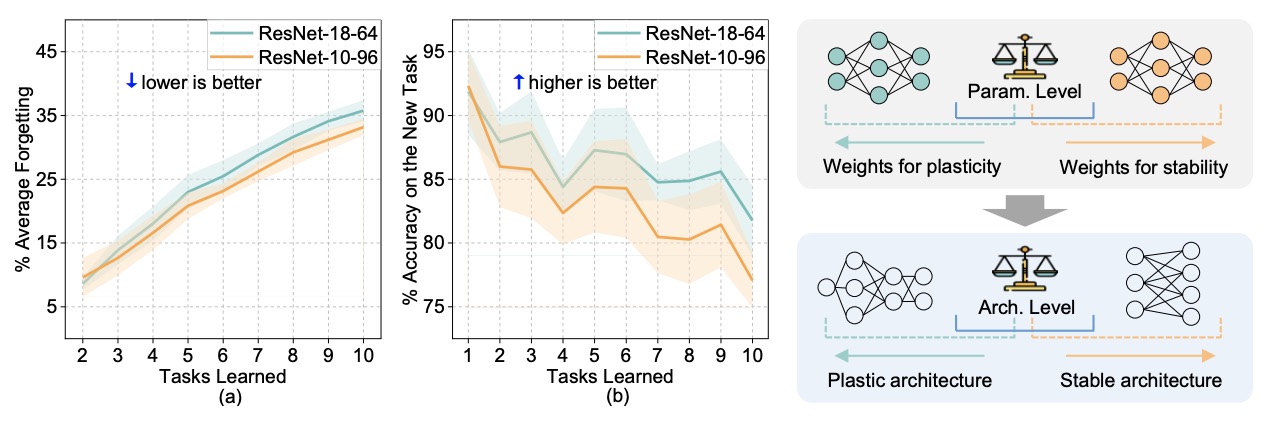
Aojun Lu, Hangjie Yuan, Tao Feng†, Yanan Sun
- We propose a novel insight for exploring the stability-plasticity tradeoff from an architectural perspective.
- We introduce a novel framework denoted DualArch, which serves as a plug-in component for continual learning.
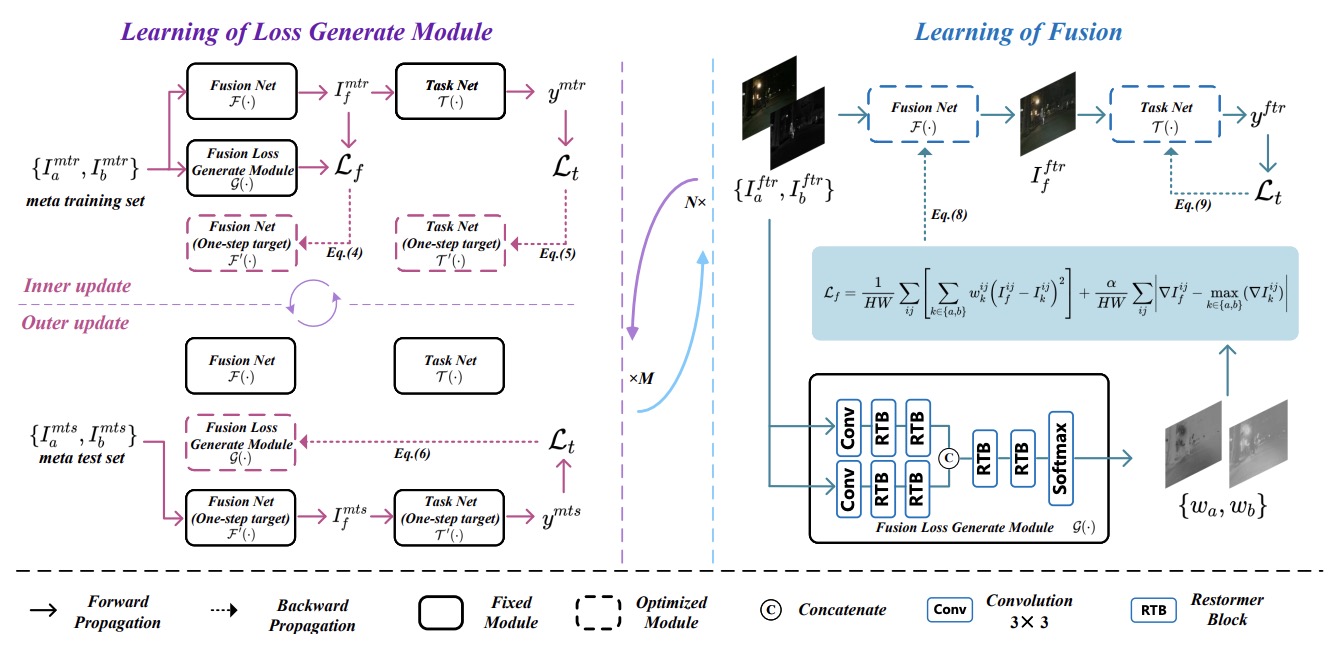
Task-driven Image Fusion with Learnable Fusion Loss
Haowen Bai, Jiangshe Zhang, Zixiang Zhao, Yichen Wu, Lilun Deng, Yukun Cui, Tao Feng, Shuang Xu
- Our framework includes a dynamically updated, learnable fusion loss generation module.
- TDFusion can be applied to any architecture of fusion and task networks.
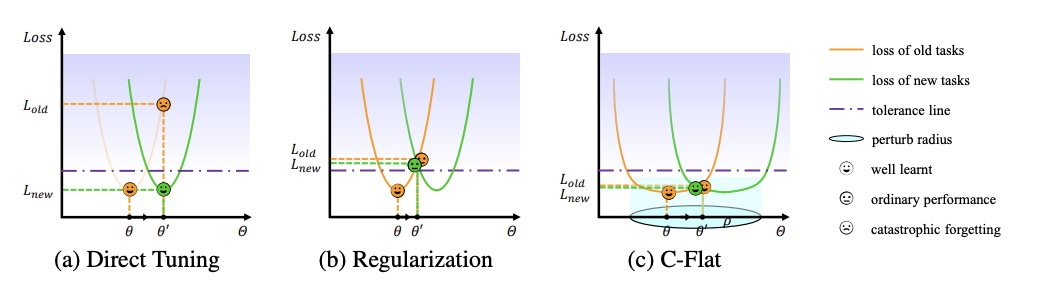
Make Continual Learning Stronger via C-Flat
Ang Bian, Wei Li, Hangjie Yuan, Chengrong Yu, Mang Wang, Zixiang Zhao, Aojun Lu, Ji Pengliang, Tao Feng†
- We propose a Continual Flatness (C-Flat) method featuring a flatter loss landscape tailored for continual learning.
- Just a line of code, Makes Continual Learning Stronger.
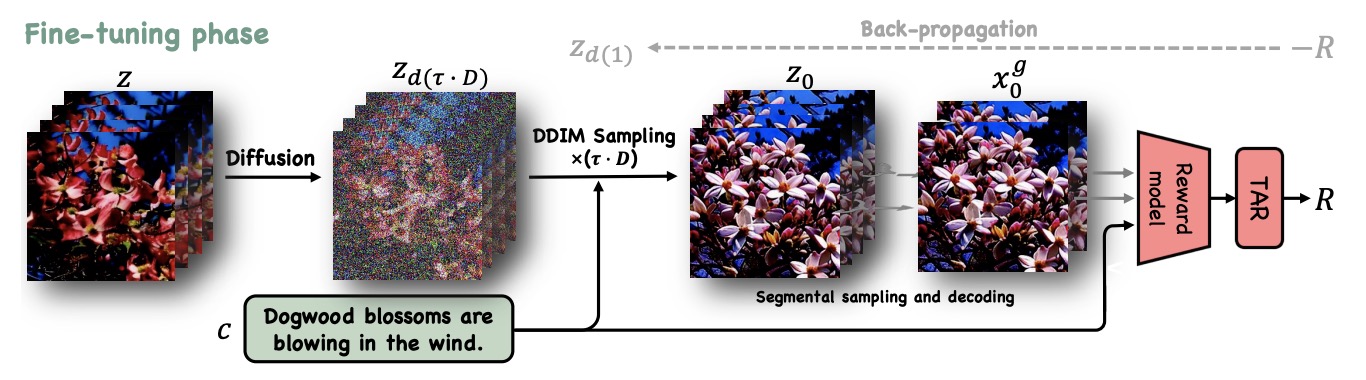
InstructVideo: Instructing Video Diffusion Models with Human Feedback
Hangjie Yuan, Shiwei Zhang, Xiang Wang, Yujie Wei, Tao Feng, Yining Pan, Yingya Zhang, Ziwei Liu, Samuel Albanie, Dong Ni
- We propose InstructVideo, a model that efficiently instructs textto-video diffusion models to follow human feedback.
- To mitigate the absence of a dedicated video reward model for human preferences, we repurpose established image reward models.
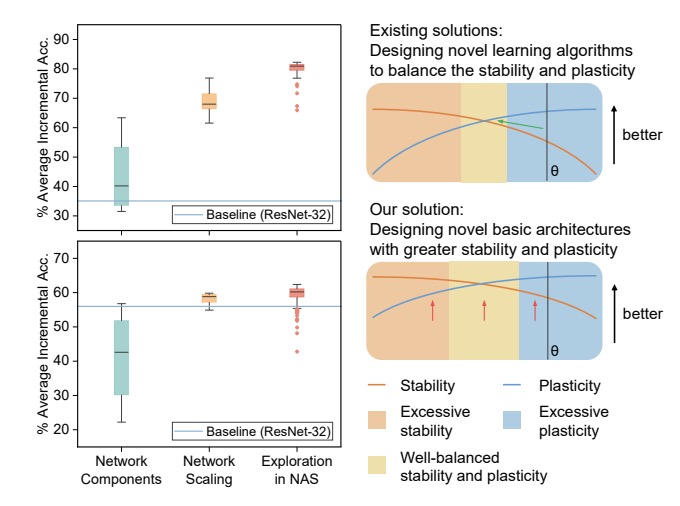
Revisiting Neural Networks for Continual Learning: An Architectural Perspective
Aojun Lu, Tao Feng, Hangjie Yuan, Xiaotian Song, Yanan Sun
- This work is the pioneering effort to employ neural architecture design to shape a CL-friendly architecture.
- We propose ArchCraft method to recraft AlexNet/ResNet into AlexAC/ResAC to guide a well-designed network architecture for CL.
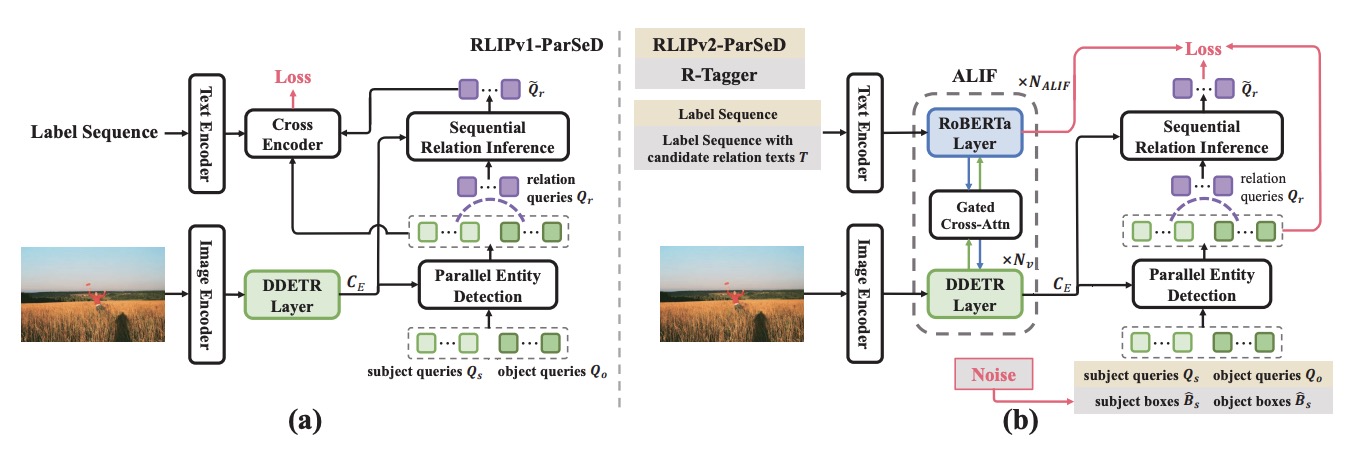
RLIP v2: Fast Scaling of Relational Language-image Pre-training
Hangjie Yuan, Shiwei Zhang, Xiang Wang, Samuel Albanie, Yining Pan, Tao Feng, Jianwen Jiang, Dong Ni, Yingya Zhang, Deli Zhao
- We propose RLIP v2, a fast converging model that enables the scaling of relational pre-training to largescale pseudo-labelled scene graph data.
- RLIPv2 introduces Asymmetric Language-Image Fusion (ALIF), a mechanism that facilitates earlier and deeper gated cross-modal fusion with sparsified language encoding layers.
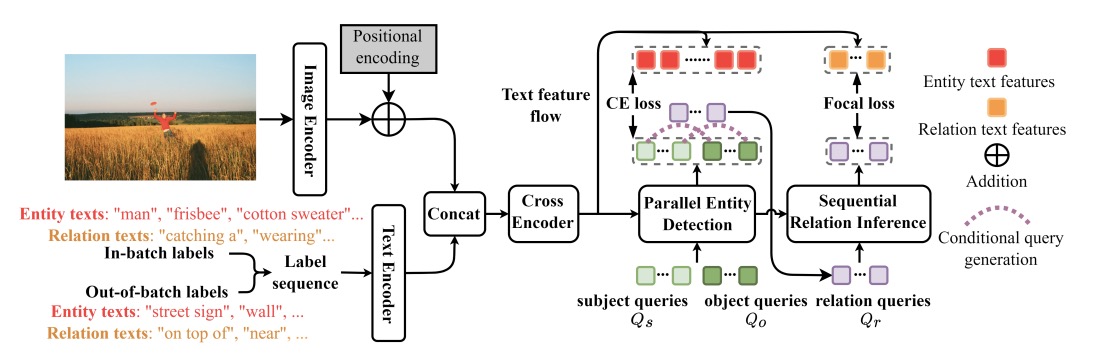
RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection
Hangjie Yuan, Jianwen Jiang, Samuel Albanie, Tao Feng, Ziyuan Huang, Dong Ni, Mingqian Tang
- We propose Relational Language Image Pre-training (RLIP), a strategy for contrastive pre-training that leverages both entity and relation descriptions.
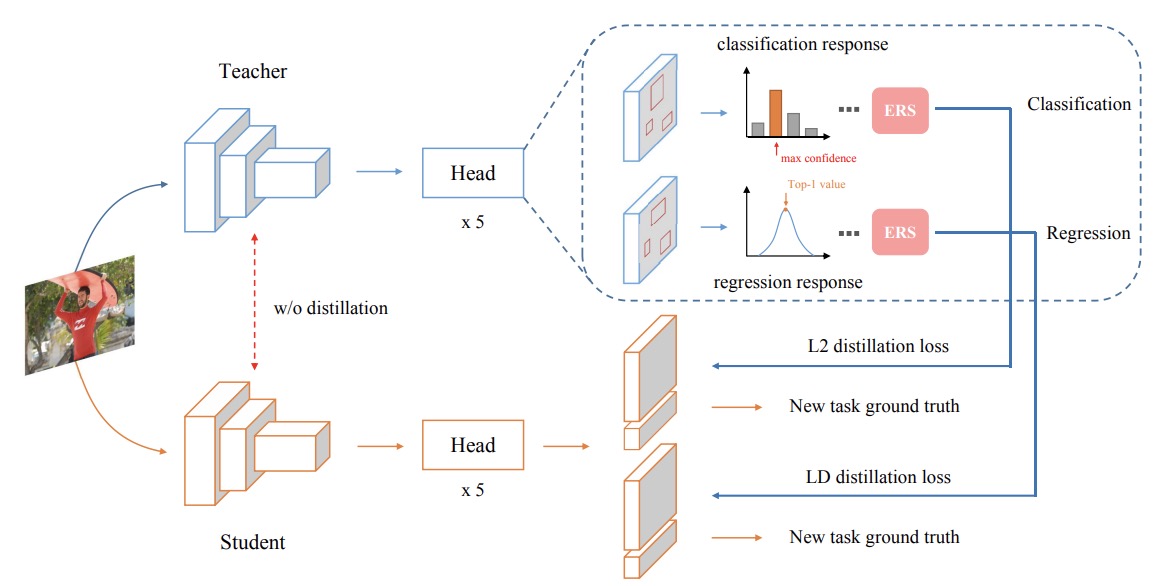
Overcoming Catastrophic Forgetting in Incremental Object Detection via Elastic Response Distillation
Tao Feng, Mang Wang, Hangjie Yuan
- First open-source incremental detection codebase.
- We propose a response-based knowledge distillation method for Incremental Object Detection, dubbed Elastic Response Distillation (ERD).
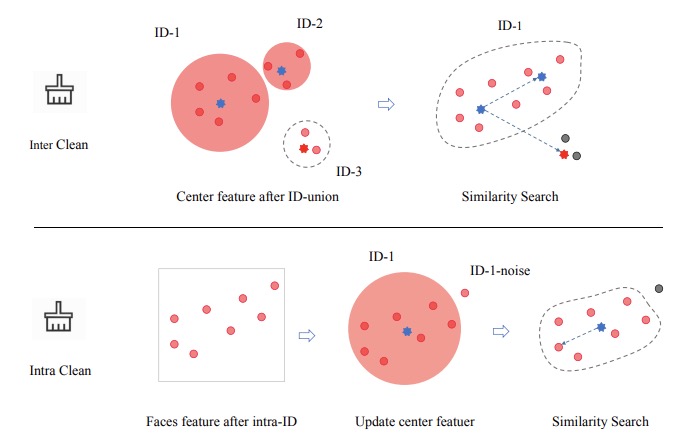
Towards Mask-robust Face Recognition
Tao Feng, Liangpeng Xu, Hangjie Yuan, Yongfei Zhao, Mingqian Tang, Mang Wang
- We introduce a mask-to-face image blending approach based on UV texture mapping, and a self-learning based cleaning pipeline for processing noisy training datasets.
- Considering the long-tail distribution and hard faces samples, a loss function named Balanced Curricular Loss is introduced.
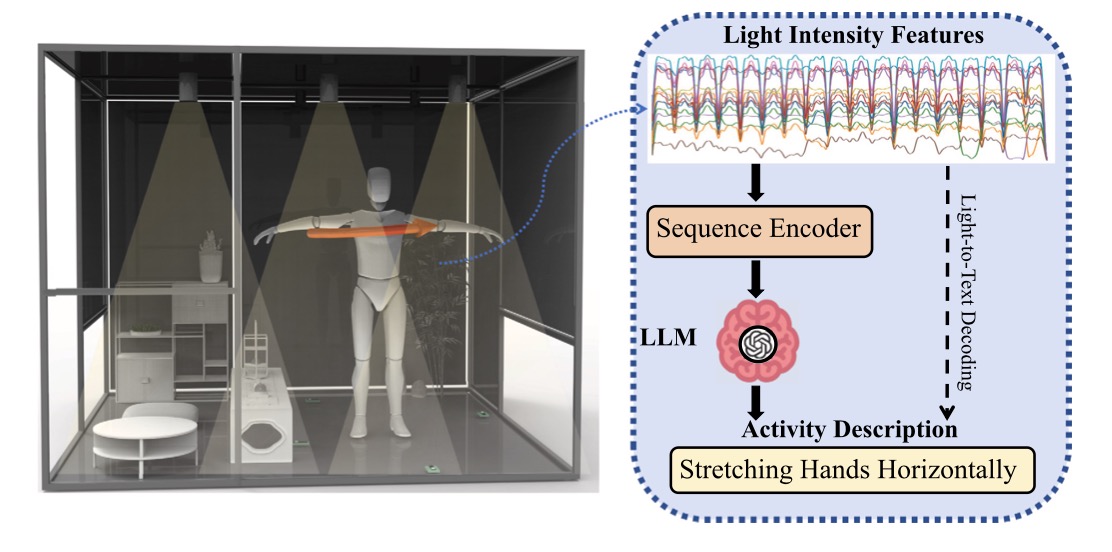
Visible Light Human Activity Recognition Driven by Generative Language Model
Yanbing Yang, Ziwei Liu, Yongkun Chen, Binyu Yan, Yimao Sun, Tao Feng†
- We propose the first HAR foundation model that leverages generative large language models (LLMs) to decode visible light feature representations into human activity descriptions.
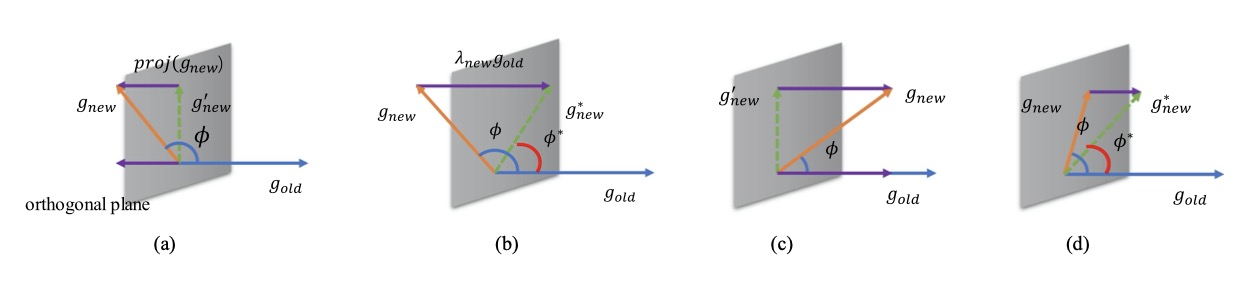
Unigrad-FS: Unified Gradient Projection with Flatter Sharpness for Continual Learning
Wei Li, Tao Feng†, Hangjie Yuan, Ang Bian, Guodong Du, Sixin Liang, Jianhong Gan, Ziwei Liu
- We propose a plug-and-play method UniGrad to tackle the inconsistency of conflicting and non-conflicting gradients in gradient updating for CL.
- We find the flat minima region through perturbing the model parameters in CL.
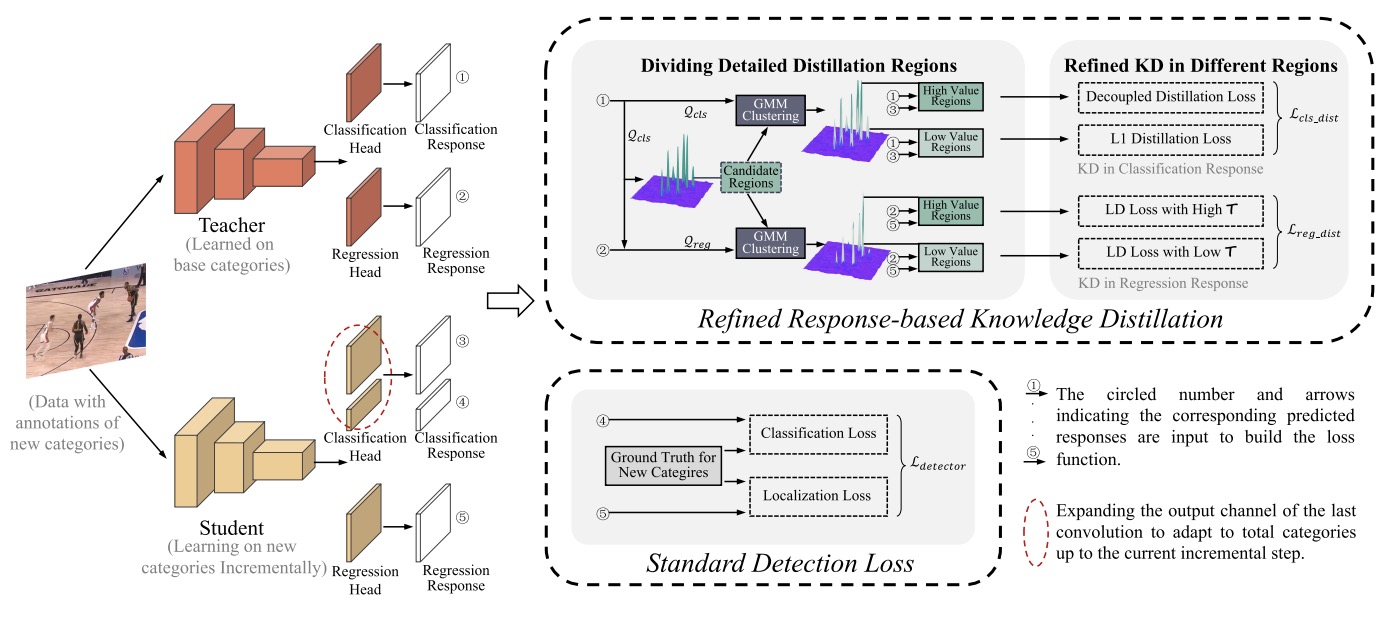
Class-Incremental Player Detection with Refined Response-based Knowledge Distillation
Liang Bai, Hangjie Yuan, Hong Song†, Tao Feng†, Jian Yang†
- We propose a refined response-based KD (R2KD) strategy specifically designed for efficient knowledge transfer in incremental detection.
- We are the first to comprehensively study class-incremental detection in real-world sports broadcast scenarios.
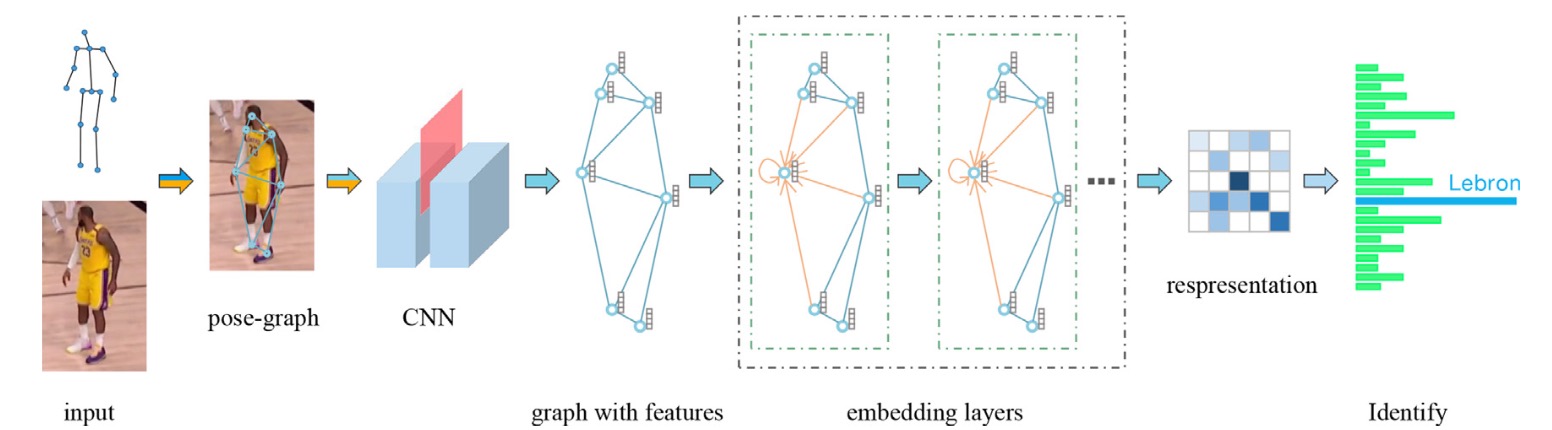
Identifying Players in Broadcast Videos using Graph Convolutional Network
Tao Feng, Kaifan Ji, Ang Bian, Chang Liu, Jianzhou Zhang
- A novel person representation method using graph convolu- tional network at the level of relational induction bias is presented.
- We innovatively embed implicit pose structure information into the deep features to form high-level features.
📖 Academic Service
- Reviewing
- Conferences: ICLR 2024-2025, ICML 2024-2025, NeurIPS 2023-2025, CVPR 2022-2024, ICCV 2023-2025, ECCV 2024, AAAI 2023-2025, IJCAI 2023-2025 ACL 2025 and KDD 2024-2025
- Journals: TPAMI, IJCV, TIP, TMM, TCSVT, TNNLS, TII, TIM and PR etc.
- Services
- Guest Editor for the Special Issue of Journal of Imaging